
Axel Kohnert
Lehrstuhl Mathematik 2
WS 2000/2001
Mit JDBC wird wird eine
Programmierschnittstelle (API Application Programming Interface) bezeichnet
die es ermöglicht aus Java Programmen mit einer Datenbank zu kommunizieren.
JDBC steht für Java Database Connectivity. JDBC ist auf SQL zugeschnitten.
Von den Fähigkeiten her ist JDBC mit embedded SQL für C vergleichbar.
JDBC ist mit der ODBC Schnittstelle unter Windows vergleichbar. Die Java
Schnittstelle JDBC ist fester Bestandteil der Programmiersprache JAVA.
Man kann JDBC als eine Low Level API bezeichnen, da lediglich SQL Anweisungen
in Java eingebunden werden. Besser (?) wäre ein direkter Zugriff auf
Datenbankobjekte (Tabellen, ..) über Java Klassen.
Das JDBC API besteht
aus zwei Teilen, dem Paket java.sql welches Datenbank unabhängig Klassen
zur Verfügung stellt um die typischen Aufgaben bei einer Datenbank
programmierung zu erledigen. Dies sind
- Verbindung aufbauen
- SQL Befehle absetzen
- Ergebnisse manipulieren
um dies zu erreichen wird mit sog. interfaces gearbeitet. Dies sind abstrakte Klassen, die erst durch Hinzunahme des zweiten Teils, den sog. Treibern implementiert werden. Die Treiber werden z.B. vom jeweiligen Hersteller der Datenbank zur Verfügung gestellt. Dadurch wird erreicht, dass JDBC Programme Datenbank unabhängig bleiben (sollten). Die oben aufgeführten Aufgaben sind innerhalb von java.sql in 3 Klassen verteilt:
- java.sql.Connection
- java.sql.Statement
- java.sql.ResultSet
Ferner gibt es noch eine vierte Klasse zur Verwaltung von Treibern:
- java.sql.DriverManager
import java.sql.*;
public class BSP1
{
public static void main(String[] argv)
{
try
{
String url = "jdbc:yardjdbc://btm2xq:1142/sample/beispiel";
Class.forName ("yardjdbc.YardDriver");
Connection con = DriverManager.getConnection(url,"DATA12","data12");
doselect(con,"select * from primzahlen where zahl<10000");
}
catch (ClassNotFoundException e)
{
System.err.println("Class not found");
System.exit(1);
}
catch (SQLException e)
{
dberror("main",e);
System.exit(1);
}
}
/*
** perform a SELECT statement
*/
static void doselect(Connection con, String stmt)
{
int ret;
try
{
Statement st = con.createStatement();
ResultSet c = st.executeQuery(stmt);
dumpResultSet(c);
}
catch (SQLException e)
{
dberror("doselect("+stmt+")",e);
System.exit(0);
}
}
/*
** perform a non SELECT statement
*/
static void dosql(Connection con, String stmt)
{
int ret;
try
{
Statement st = con.createStatement();
ret = st.executeUpdate(stmt);
}
catch (SQLException e)
{
dberror("dosql("+stmt+")",e);
System.exit(0);
}
}
static
void dumpResultSet(ResultSet rs) throws SQLException
{
ResultSetMetaData md = rs.getMetaData();
int i, cols = md.getColumnCount();
int row = 0;
for (i=0;i<cols;i++)
System.out.println("Column " + i + ": " +
md.getColumnName(i+1));
while (rs.next())
{
System.out.print(row+++": ");
for (i=0;i<md.getColumnCount();i++)
System.out.print(rs.getString(i+1)+" ");
System.out.println();
}
}
/*
** Report the SQLCODE if an error occurs
*/
static void dberror(String loc, SQLException e)
{
System.err.println(loc + ": ");
e.printStackTrace();
do
{
System.err.println(e.getErrorCode()+
"("+e.getSQLState()+
")"+": "+e.getMessage());
e = e.getNextException();
}
while (e != null);
}
}
Der erste Schritt ist das
explite Laden des Treibers, dies ist nötig um die Funktionen aus java.sql
mit Leben zu Füllen. Dies geschieht mit dem Aufruf
Class.forName
("yardjdbc.YardDriver");
Dazu muss natürlich
die entsprechende Klasse gefunden werden (CLASSPATH). Danach wird mit dem
Datenbanksystem eine Verbindung aufgebaut. Dazu gibt es das Connection
Objekt.
Zum Anmelden bei der Datenbank gibt es ein sog. JDBC URL bestehend aus
Treiberspezifikation und DatenbankSystem und Datenbank. Ausser dem URL
muss noch Benutzer und Passwort angegeben werden. Das Connection Objekt
welches man erhält ist im nächsten Schritt wichtig wenn man über
diese Verbindung Befehle an die Datenbank schickt. Da SELECT Befehle im
Gegensatz zu anderen SQL Befehlen ein Ergenis erzeugen wird dies in der
Routine doselect abgehandelt. Egal um welchen Befehl es sich handelt wird
die Anfrage von einem Statement Objekt erledigt.
Statement st =
con.createStatement();
Dabei wird von der zuvor
erzeugten Verbindung ausgegangen. Mit dem Befehl
ResultSet c = st.executeQuery(stmt);
erhält man das dritte
Objekt, das Ergebnis des SELECT Befehls ein ResultSet Objekt. Die Navigation
innerhalb des ResultSet Objekts geschieht wie mit einem Cursor (auch schon
aus Embedded SQL für C bekannt). Dies geschieht in der Routine dumpResultSet.
Um Informationen über das Ergebnis zu bekommen bedient man sich der
der Klasse
ResultSetMetaData,
die Informationen über
das ResultSet enthält, so die Anzahl der Spalten
getColumnCount()
und die Namen
getColumnName()
der Spalten. Die Zeilen des
Ergebnis können nur mittels der Methode
next()
durchlaufen werden, die solange
true liefert wie noch eine Zeile gelesen werden kann. Die Spalten werden
mit 1,2... durchnummeriert, und es geibt verschiedene Methoden
getString(), getDouble(),
..
um aus den Spalten innerhalb
der aktuellen Zeile zu lesen. Im Beispiel werden die Einträge als
Strings ausgegeben. Man kann Statement und ResultSet explizit Löschen
mit der Methode close() oder dies passiert automatisch am Ende der Lebenszeit
der Objekte. Die Fehlerbehandlung passiert mit einem Objekt der Klasse
SQLException
die mittels try / catch abgefangen
werden können. Im Beispielprogramm wird dazu die Routine dberror()
aufgerufen. Die zweite Routine dosql() wird verwendet wenn ein nonSELECT
Befehl ausgeführt werden soll. Dafür gibt es die Methode
executeUpdate()
für ein Statement Objekt.
Im Falle eines wirklichen UPDATE/INSERT/DELETE liefert es die Anzahl der
betroffenen Zeilen. Im Falle von DDL Befehlen (CREATE TABLE,..) den Wert
0. Es ist noch zu bemerken, dass ein paar wenige SQL Befehle, nämlich
für die Transaktionssteuerung innerhalb der Klasse Connection erledigt
werden, und nicht über ein Statement Objekt.
Der erste Schritt ist
immer das Anmelden eines Treibers, dies geschieht mit der Klasse:
java.sql.DriverManager
die Methoden im Zusammenhang
mit Treibern zur Verfügung stellt. Die Methoden sind statisch, da
nur ein Treibermanager existieren darf. Folgendes wird ermöglicht:
- Registrieren und Laden
von Treibern
- Herstellung einer Verbindung
zu einer Datenbank
- Konfigurieren der Verbindung
Zum Laden gibt es zwei Möglichkeiten:
explizit wie im Beispiel mit dem Aufruf Class.forName, oder beim Aufruf über die System Eigenschaft sql.drivers, d.h. der Aufruf lautet
java -Dsql.drivers=....
Es gibt auch Situation wo
man direkt mit dem Treiber arbeiten muss. Man erhält den Treiber mit
der Methode
static Driver getDriver(String
url) throws SQLException
aus der Klasse DriverManager.
Mit einem Driver Objekt kann man überprüfen ob diese Version
JDBC konform ist:
boolean jdbcCompilant()
oder man kann die Version
überprüfen
int getMajorVersion()
int getMinorVersion()
und man kann auch explizit
einen Treiber wieder abmelden
void deregisterDriver()
das korrespondierende registerDriver
wird automatisch beim Laden gemacht. Eine letzte Verwendung von DriverPropertyInfo
Objekten, dies funktioniert prinzipiell mit allen Treibern, nicht nur JDBC
Treibern
DriverPropertyInfo[] getPropertyInfo
(String url, ..) throws SQLException
und ein DriverPropertyInfo Objekt hat folgende Attribute
name
value
description
required
boolean
choices
ein array mit möglichen Werten
und man kann die Informationen wie folgt abfragen:
try
{
String url = "...";
Class.forName (url);
Driver theDriver = DriverManager.getDriver(url);
DriverPropertyInfo[] props =
theDriver.getPropertyInfo(url,null);
for (int i=0;i<props.length;i++)
if (props[i].required)
System.out.println(props[i].name + ":"+
props[i].description);
}
Verbindung zur Datenbank
Nach dem Laden des Treibers
ist der nächste Schritt der Aufbau der Verbindung zur Datenbank. Die
Methoden hierfür werden vom DriverManager zur Verfügung gestellt:
Connection getConnection(String
URL) throws SQLException
haben wir im Beispiel schon
kennengelernt. Ein URL (uniform resource locator) zum Aufbau einer Verbindung
ist wie folgt aufgebaut
jdbc:<Protokoll>:<Datenbank>
das Protokoll ist treiberspezifisch und der dritte Teil dient zur Auswahl der Datenbank, enthält also den Rechnernamen wenn es über Netz geht, legt fest welches Datenbanksystem angesprochen wird und dann eventuell die ausgewählte Database (SQL Befehl DATABASE). Im Beispiel war das Protokoll der YARDTreiber yardjdbc, es wurde über Netz auf den Rechner btm2xq am Port 1142 zugegriffen und es wurde die database beispiel im System sample angesprochen.
String url = "jdbc:yardjdbc://btm2xq:1142/sample/beispiel";
Es kann sich beim Aufbau
der Verbindung auch gleich eingeloggt werden:
Connection getConnection(String
URL,String user, String passwd) throws SQLExceception
und es geht auch über
properties:
Connection getConnection(String
URL, java.util.Porperties info) throws SQLExceception
wie man an folgenden Codefragment
sieht:
Properties p = new Properties();
String url = "...";
p.put("user","DATA12");
p.put("password","data12");
Connection c = DriverManager.getConnection(url,p);
Da es möglich ist
mehrere Treiber zu verwenden wird beim Audfbau der Verbindung getestet
bis ein passender Treiber gefunden wurde. Dazu gibt es die Methode acceptsURL
in java.sql.Driver.
Timeouts, Tracing
In der Klasse DriverManager
gibt es Methoden zur Manipulation der Wartezeit beim Verbindungsaufbau.
Dies sind
getLoginTimeout()
void setLoginTimeout(int
sekunden)
Ferner hat man die Möglichkeit
in der Klasse DriverManager einen Stream zum Protokollieren der Treiberoperationen
zu setzen.
java.io.PrintStream getLogStream()
void setLogStream(java.io.PrintStream
out)
wird bei setLogStream der
Wert null übergeben wird das Protokollieren wieder ausgeschaltet.
Connection
Ein Connection Objekt repräsentiert
eine Verbindung zu einer Datenbank. Es kann davon mehrere geben. Erzeugt
wird ein Connection Objekt mit der Methode getConnection aus der DriverManager
Klasse. Das Connection wird hauptsächlich dazu verwendet SQL Befehle
an die Datenbank zu senden. In der Connection Klasse git es die Methoden
setCatalog(String Catalog)
throws SQLException
String getCatalog() throws
SQLException
damit kann zwischen verschiedenen
'Katalogen' gewechselt werden. Unter Katalog versteht man ein Organisationseinheit
oberhalb von DATABASE und wird selten verwendet. Das Methodenpaar
setReadOnly(boolen readOnly)
throws SQLException
boolean isReadOnly()
throws SQLException
dient dazu eine Connection
auf readonly zu schalten, das bedeutet das hierüber keine Schreiboperationen
an der Datenbank möglich sind. Zum Beispiel kann es so möglich
sein die SQL Operationen anders zu optimieren. Um eine Verbindung
zu beenden gibt es
void close() throws SQLException
boolean isClosed() throws
SQLException
diese Methode wird automatisch
am Ende der Lebenszeit eines Conneciton Objekts aufgerufen. Es wird aber
empfohlen es stets selber zu tun. Dies setzt auch resourcen auf Seiten
des Datenbanksystems frei.
Transaktionen
Auch die Befehle zur Transaktionssteuerung
sind als Methoden in der Klasse Connection angesiedelt.
void commit() throws SQLException
void rollback() throws
SQLException
Wird ein neues Connection
Objekt erzeugt ist dies im soge. auto-commit-Modus, das bedeutet nach jeder
Anweisung wird automatisch ein Commit durchgeführt (anders als bisher
vorgestellt). Dies kann man ändern mit den Methoden
void setAutoCommit (boolean
enable) throws SQLException
boolean get AutoCommit()
throws SQLException
Nach dem Ändern dieser Einstellung kann man erst wirkliche Transaktionsverarbeitung unter JDBC machen. Speziell ist es also in der default Einstellung nicht möglich SQL Befehle in JDBC rückgängig zu machen.
Ein Beispielprogrammausschnitt:
wenn nun während der drei SQL Befehle ein Fehler auftritt (es wird SQLException geworfen) wird ein rollback gemacht und der Fehler weitergereicht. D.h. die drei Befehle werden als Transaktion durchgeführt.
try {
stmt = c.createStatement();
c.setAutoCommit(false);
stmt.executeUpdate(..);
stmt.executeUpdate(..):
stmt.executeUpdate();
c.commit();
} catch (SQLException e) {
c.rollback();
throw e;
}
ACID
Bei den Transaktionen gibt es einen Standard und eine Theorie dahinter. Eine Transaktion ist definiert als eine Folge von Aktionen die die Datenbank von einen definierten Zustand in einen neuen definierten Zustand überführt. Dabei soll das ACID Prinzip gelten:
Atomicity: d.h. ununterbrechbar, es kann nicht passieren dass eine Transaktion nur
teilweise ausgeführt wird
Consistency: d.h. nach einer Transaktion ist die Datenbank vernünftig
Isolation: es wird der isolierte Ablauf verlangt, d.h. es ist egal ob eine Transaktion einzeln
oder parallel mit anderen läuft. Man spricht auch von serializable, d.h. das
Ergebnis muss gleich sein egal in welcher Reihenfolge die Transaktionen
ablaufen.
Durability: nach der Transaktion muss das Ergebnis sicher sein.
dies sind Wünsche
an eine Transaktion, SQL Datenbank erlauben die Dinge aus Laufzeitgründen
lockerer zu handhaben. Es gibt verschiedenen Isolationsebenen die diese
Restriktionen aufheben.
read uncommitted:
erlaubt bei nur Lese Transaktionen den Zugriff auf noch nicht geschriebene
Daten (dirty read)
read committed:
erlaubt nur das Lesen von endgültig geschriebenen Daten (commited),
man hat aber noch das Problem der non repeatable reads.
repeatable reads:
dieses Problem taucht auf, wenn zwei Transaktionen das gleiche Objekt brauchen.
Die erste liest es, die zweite ändert es, die erste liest es nochmal,
und jetzt ist es aber geändert, ein non repeatable read. Dies wird
auf diesem Isolationslevel verhindert. Es gibt aber immer noch das Phantomproblem.
serializable: Damit
wird wirklich erreicht, das sich zwei Transaktionen in die Quere kommen.
Ein Phantom ist ein Objekt das existieren kann, aber nicht während
der Gesamtdauer der Transaktion da ist. Wenn z.B. ein COUNT gemacht wird
und während dieser Transaktion ein eine andere Transaktion ein weiteres
passendes Objekt einfügt.
Um diese Isolationsebenen
(d.h. die Transaktionen sind unterschiedlich isoliert voneinander) zu realisieren
gibt es in der Connection Klasse:
static int TRANSACTION_NONE
static int TRANSACTION_READ_UNCOMMITTED
static int TRANSACTION_READ_COMMITTED
static int TRANSACTION_REPEATABLE_READ
static int TRANSACTION_SERIALIZABLE
void setTransactionIsolation(int
level) throws SQLException
int getTransactionIsolation()
throws SQLException
das level TRANSACTION_NONE
bedeutet das vom System keine Transaktionen unterstützt werden.
Es gibt drei Klassen
von Anweisungen
dies sind normale Anweisungen, prepared Statements und stored procedures (schon bekannt aus dem Abschnitt über embedded SQL für C).
java.sql.Statement
java.sql.PreparedStatement
java.sql.CallableStatement
Um diese Objekte zur Erzeugen
gibt es in der Connection Klasse die Methoden:
Statement createStatement()
throws SQLException
PreparedStatement prepareStatement(String
sql) throws SQLException
CallableStatement prepareCall(String
sql) throws SQLException
Bei dem 'normalen' Statement
wird der SQL Befehl erst beim Ausführen angegeben, im Gegensatz zu
den beiden anderen wo bereits vorher der Befehl angegeben werden muss.
Ausführen von Befehlen
Es gibt in der Klasse Statement
drei Methoden zum Ausführen eines SQL Befehls;
ResultSet executeQuery(String
sql) throws SQLException
int executeUpdate(String
sql) throws SQLException
boolean execute(String
sql) throws SQLException
die ersten beiden Methoden
wurden schon im ersten Beispiel vorgestellt, executeQuery wird für
ein Select verwendet, wenn eine Tabelle als Ergebnis geliefert wird. Die
zweite Methode dient für DDL und DML Befehle. Bei DML ist der Rückgabewert
die Anzahl der betroffenen Zeilen und im Falle von DDL ist der Rückgabewert
0. Die dritte Methode wird verwendet wenn ein Aufruf mehrere Ergebnisse
liefert, z.B. beim Aufruf einer stored procedure. Das Ergebnis ist true
wenn das Ergebnis ein ResultSet ist und false wenn es ein Integerwert ist,
z.b. ein Updatezähler. Man kann auf diese mit folgenden Methoden aus
Statement zugreifen:
ResultSet getResultSet()
throws SQLException
int getUpdateCount()
throws SQLException
boolean getMoreResults()
throws SQLException
interessant ist dabei getMoreResults() denn durch einen Rückgabewert wie bei der Methode execute() wird mitgeteilt ob noch weitere Ergebnisse anstehen. getResultSet() liefert die nächste Tabelle oder null wenn keine Tabelle mehr anliegt. getUpdateCount() liefert -1 wenn keine Zahl mehr anliegt. D.h. man hat alle Ergebnisse wenn gilt
(getMoreResults() == false)
&& (getUpdateCount() == -1)
Escape-Klauseln
Ein Problem bei plattformunabhängigen JDBC Programmen ist die Tatsache, dass sich die unterschiedlichen Datenbanksystemen sher wohl unterscheiden. Ein typische Beispiel ist die Datumsnotation. D.h. die JDBC Programme sind gleich, aber müssen unterschiedlich SQL Anweisungen mit z.B. executeQuery abgeschickt werden. Dazu gibt es sog. Escape Klauseln, diese werden innerhalb des SQL Befehls der z.B. an executeQuery übergeben wird eingesetzt. Diese werden vom Treiber erkannt und entsprechend umgesetzt, sodass bei der Datenbank der richtige Befehl ankommt. Eine Escape Klausel sieht wie folgt aus:
{ keyword parameter }
an Schlüsselwörten gibt es u.a.
| escape | Metazeichen bei LIKE |
| d | Datum |
| t | Zeit |
| call | Aufruf für stored procedure |
| oj | outer join |
| .. |
CallableStatement stmt= c.prepareCall("{ call MultipleResultsProc}");
stmt.execute();
while (stmt.getMoreResults()) {
ResultSet rs = stmt.getResultSet();
....
}
dabei wurde die Escape
Klausel verwendet um wirklich plattformunabhängig bleiben zu können.
Einstellungen bei der Ausführung
Man kann Parameter bei der
Ausführung festlegen. Mit setQueryTimeout() kann man festlegen wie
lange in Sekunden auf eine Antwort bei einer Query gewartet werden soll.
Default ist 0, was unendlich bedeutet. Bei den Ergebnistabellen kann man
mit setMaxRows die maximale Anzahl der Zeilen festlegen. Bei den Spalten
vom Typ CHAR/VARCHAR/LONGVARCHAR/VARBINARY/LONGVARBINARY kann man die maximale
Anzahl der Bytes mit setMaxFieldSize festlegen. In beiden Fällen bedeutet
der Defaultwert 0 wieder ohne Beschränkung.
int getMaxFieldSize()
throws SQLException
void setMaxFieldSIze(int
max) throws SQLException
int getMaxRows()
throws SQLException
void setMaxRows()
throws SQLException
int getQueryTimeout()
throws SQLException
void setQueryTimeout()
throws SQLException
Zuletzt noch zwei Methoden,
wie schon bei der Connection gibt es eine close() Methode, die auch gegenüber
der automatischen garbagecollection bevorzugt werden sollte. Eine weitere
interessante Methode ist
void cancel() throws
SQLException
damit kann man ein laufendes
statement aus einem zweiten thread heraus abbrechen.
PreparedStatement
Auch in JDBC kann man mit
Prepared Statements arbeiten. Auch dies ist aus dem Abschnitt Embedded
SQL für C bekannt. Es gitb Laufzeitvorteile. Man hat auch die Möglichkeit
an ein vorübersetztes SQL statement verschiedene Parameter übergeben.
Ein Fragezeichen dient dabei als Platzhalter. Dies funktioniert auch in
JDBC. Um vor dem eigentlichen Aufruf die Platzhalter zu Füllen gibt
es verschiedene setXXX Methoden.
void setBoolean(int index,
boolean b) throws SQLException
void setString(int index,
String s) throws SQLException
void setInt(int index,
int i) throws SQLException
.....
die Vorgehensweise kann man
am folgende Beispiel studieren:
PreparedStatement stmt = c.prepareStatement("INSERT INTO book "+Obwohl die Klasse PreparedStatement von der Klasse Statement abgeleitet wurden die execute Methoden neu geschreiben, da sie hier keinen Parameter erwarten. Der SQL Befehl wurde ja schon beim 'preparen' übergeben. Um NULL Werte einzufügen oder um grosse Datenmengen einzufügen gibt es spezielle Methoden
"VALUES (?,?,?,?,?,?)");
stmt.SetString(1,"3-608-93421-9");
stmt.SetDouble(5,49.90);
...
stmt.executeUpdate();
void setNull(int index,
int jdbcType) throws SQLException
void setAsciiStream(int
index, java.io.InputStream s, int length) throws SQLException
void setBinaryStream(int
index, java.io.InputStream s, int length) throws SQLException
void setUnicodeStream(int
index, java.io.InputStream s, int length) throws SQLException
Bei setNull muss der JDBC
Datentyp angegeben werden, hierfür git es in java.sql.Types vordefinierte
Konstanten:
| CHAR,VARCHAR,LONGVARCHAR | Zeichenketten |
| BIT | Bit |
| BINARY,VARBINARY,LONGVARBINARY | Binärfelder |
| TINYINT,SMALLINT,BIGINT,INTEGER | Ganzzahlen |
| REAL,FLOAT,DOUBLE | Gleitkommazahlen |
| DECIMAL,NUMERIC | Dezimalzahlen |
| DATE,TIME,TIMESTAMP | Datum,Uhrzeit |
Bei den Stream Methoden wird ein geöffneter Stream übergeben und die Anzahl der Bytes, die daraus gelesen werden sollen. Bei ASCII und Unicode muss auf der Datenbankseite eine Zeichenkette erwartet werden, bei Binary muss auf der Datenbankseite ein Binärfeld erwartet werden. Zur Illustration ein Beispiel:
CallableStatement
File content = new File("cover.jpd");
String isbn = "3-..";
int len = content.length();
FileInputStream fin = new FileInputStream(content);
PreparedStatement stmt = con.prepareStatement("UPDATE book SET cover =?"+
"WHERE ISBN = ?");
stmt.setBinaryStream(1,fin,len);
stmt.setString(2,isbn);
stmt.excuteUpdate();
Dies ist die nächste
Stufe, und diese Klasse wird wiederum vom PreparedStatement abgeleitet.
Anders als ein preparedStatement ist dies ein persistentes Objekt, d.h.
es lebt in der Datenbank auch nach dem Abmelden weiter. Hier handelt es
sich um zuvor gespeicherte Funktionen oder Prozeduren. Parameter dienen
zur Kommunikation (Übergabe von Werten (IN) oder Rückgabe von
Werten (OUT) oder sogar beides (INOUT). Bei Funktionen kann es sogar einen
Rückgabewret geben. Wieder dien ? als Platzhalter. Zum Beschreiben
der Eingabeparameter dienen die bekannte setXXX Methoden aus der Klasse
PreparedStatement. Bei den OUT oder INOUT Parametern müssen
diese vor der Ausführung in ihrem JDBC Typ festgelegt werden. Dazu
gibt es in der Klasse CallableStatement die Methode
void registerOutParameter(int
index, int jdbcType) throws SQLException
ein Beispiel bei dem eine
Prozedur aufgerufen wird mit zwei Parameter, der zweite ist ein INOUT vom
Typ FLOAT, der erste ein OUT Parameter vom Typ VARCHAR
CallableStatement stmt = con.prepareCall("{call TestProc(?,?)}");Jenachdem von welchen Typ die Prozedur ist (SELECT / UPDATE / ..) kommen zum Ausführen executeQuery, executeUpdate, execute in Frage.
stmt.setDouble(2,42.0);
stmt.registerOutParameter(1,java.sql.Types.VARCHAR);
stmt.registerOutParameter(2,java.sql.Types.FLOAT);
Zum Auslesen des Ergebnis
aus einem Parameter gibt es getXXX Methoden
int getInt(int index)
throws SQLException
float getFloat(int index)
throws SQLException
String getString(int
index) throws SQLException
....
es ist aber zu beachten,
dass
es keine Methoden für streams gibt. Mit der Methode
boolean wasNull() throws
SQLException
kann man überprüfen
ob der zuletzt mit getXXX gelesene OUT Wert ein NULL Wert war. Um obiges
Beispiel auszuführen und das Ergebnis zu Lesen:
con.executeUpdate();
double res = stmt.getDouble(2);
boolean next() throws SQLException
um auf die nächste Zeile im ResultSet zuzugreifen. Am Anfang steht der Cursor vor der ersten Zeile. D.h. zuerst ist ein next nötig.
Statement s = c.createStatement();
ResultSet r = s.executeQuery("...");
while (r.next()) {
..
}
r.close();
void close() throws
SQLException
sollte ebenso wie bei Statement und Connection verwendet werden. Wenn der Cursor positioniert ist kann man in der aktuellen Zeile der Tabelle auf die Einträge in den Spalten zugreifen. Beim Zugriff kann mit dem Spaltennamen indizieren oder über den Spaltenindex, wobei die erste Spalte den Index 1 hat. Um vom Spaltennamen zum Index zu kommen gibt es die Methode
int findColumn(String name) throws SQLException
um auf die Daten zuzugreifen gibt es (wie auch schon teilweise beim callableStatement) die Methoden
String getString(int index)
throws SQLException
String getString(String
name) throws SQLException
int getInt(int index)
throws SQLException
int getInt(String name)
throws SQLException
...
Dazu eine nützliche
Tabelle(aus Dehnhardt: Anwendungsprogrammierung mit JDBC)
Damit werden alle getXXX Methoden aufgeführt und welche JDBC Typen wie in Java Typen umgewandelt werden können. Noch ein Beispiel für den Zugriff mittels getXXXStream. Es zeigt wie man ein Bild aus der Datenbank bekommt und es anzeigt. Verwendet werden JPEG Klassen von Sun
Ein Problem sind noch die NULL Werte, ebenso wie beim callableStatement muss dies explizit getestet werden
ResultSet r = s.executeQuery("SELECT cover FROM book WHERE isbn="+
"'3-608-93421-9'");
while (r.next()) {
java.io.InputStream i = rset.getBinaryStream(1);
JPEGImageDecode d = JPEDCodec.createJPEGDecoder(i);
BufferedImage image = d.decodeAsBufferedImage();
// buffered image anzeigen
}
boolean wasNull() throws SQLException
getestet werden muss wenn bei Objekten (getString, getDate, ...) null zurückkam, bei getBoolean false oder der Wert 0 bei getInt, getDouble, ...
ResultSetMetaData
Wichtige weitere Informationen über das ResultSet werden in der Klasse ResultSetMetaData versteckt. Wichtig ist dies zum Beispiel bei Anwendeungen, wo nicht klar ist welche Attribute und welche Datentypen in einer Tabelle anliegen. Z.B. bei einer Anwendung wo der Benutzer Verbindungen zu einer beliebigen Datenbank aufbauen kann. Ein Objekt der Klasse ResultSetMetaData wird durch die Methode
ResultSetMetaData getMetaData() throws SQLException
aus der Klasse ResultSet erzeugt. In der Klasse ResultSetMetaData gibt es verschiedene Methoden
int getColumnCount() throws
SQLException
String getTableName (int
index) throws SQLException
String getCoulmnName(int
index) throws SQLException
int getColumnType(int
index) throws SQLException
String getColumnTypeName(int
index) throws SQLException
boolean isReadOnly(int
index) throws SQLException
boolean isWriteable(int
index) throws SQLException
boolean isNullable(int
index) throws SQLException
...
Die Methode getColumnCount liefert die Anzahl der Spalten im ResultSet, getTableName liefert den Namen der Tabelle aus der die Spalte stammt, getColumnName den Attributnamen zur Spalte, getColumnTaype den JDBC Typ, d.h. ein Vergleich auf INTEGER ist möglich. Den Namen des Datentyps bekommt man über getColumnTypeName. Die letzten drei Methoden testen ob nur lesbar ob auch geschrieben werden kann und ob NULL Werte in der Spalte erlaubt sind. Ein vollständige Übersicht ist unter dem URL
http://java.sun.com/products//jdk/1.1/docs/api/java.sql.ResultSetMetaData.html
erhältlich. Noch ein
Beispiel zur Verwendung des Objekts ResultSetMetaData.
ResultSet r = s.executeQuery(" .. ");
ResultSetMetaData rm = r.getMetaData();
int numcols = rm.getColumnCount();
for (int i = 1; i<=numcols;i++) {
int ct = rm.getColumnType(i);
String cn = rm.getColumnName(i);
String ctn = rm.getColumnTypeName(i);
System.out.println("Spalte #"+i+":"+cn+" vom Typ "+ctn+
" (JDBC Typ: "+ct);
}
DatabaseMetaData
Ähnlich den ResultSetMetaData gibt es noch eine Klasse DataBaseMetaData, diese erhält man wenn man in der Klasse Connection mit
DatabaseMetaData getMetaData() throws SQLException
arbeitet. In dieser Klasse gibt es eine riesige Anzahl von Methoden die helfen sollen Informationen über das Datenbanksystem zu bekommen. Man erhält so auch Zugriff auf das Data Dictionary, eine DATABASE mit Informationen über das Datenbank System. Ein kleiner Ausschnitt aus der Menge der verfügbaren Methoden
String getURL() throws
SQLException
String getDataBaseProductName()
throws SQLException
String getDataBaseProductName()
throws SQLException
um 'technische' Informationen über die Datenbank zu bekommen. Mit den nächsten Methoden erhält man Informationen über das SQL, das von dieser Datenbank unterstützt wird.
String getSQLKeywords()
throws SQLException
String getStringFunctions()
throws SQLException
String getNumericFunctions()
throws SQLException
liefert eine Aufstellung (string mit Komma getrennt) von SQL Befehlen und Funktionen
boolean supportsOuterJoins()
throws SQLException
boolean supports AlterTableWithAddColumn()
thrwos SQLEXECPTION
So können Eigenschaften abgefragt werden, in denen sich (leider) SQL Versionen bei verschiedenen Datenbankanbietern unterscheiden. Die weiteren Methoden betreffen eher Limitierungen des Treibers (nicht nur)
int getMaxConnections()
throws SQLException
int getMaxColumnsInTable()
throws SQLException
int getMaxColumnsInSelect()
throws SQLException
...
0 bedeutet hier im unbeschränkt. Und im Gegensatz zu den ähnlichen Methoden in der Connection Klasse gibt es hier kein setXXX. Die letzte Gruppe von Methoden arbeitet mit dem Data Dictionary. Sie liefern ResultSet Objekte:
ResultSet getTables getTables(String
catalog, String schemapattern,
String tablepattern, String types[]) throws SQLException
ResultSet getProcedures(String
catalog, String schemapattern,
String procedurenamepattern) throws SQLException
ResultSet getProcedureColumns(String
catalog,String schemapattern,
String procedureNamePattern, String columnNamePattern)
throws SQLException
ResultSet getColumns(String
catalog, String schemaPattern,
String tableNamePattern, String columnNamePattern)
throws SQLException
...
Die Vorgehensweise ist überall
ähnlich, man benötigt einen Katalog (getCatalog aus der Connection
Klasse) kann dann ein Schema (DATABASE) oder auch nur ein Pattern angeben,
die Rückgabe sind jeweils die matchenden Objekte. Als ein Beispiel
sollen alle Tabellen und Views aus der spezifizierten Datenbank
ausgegeben werden:
public class Schema {
public static void printSchema (Connection con, String schema)
throws SQLException {
DatabaseMetaData db_meta = con.getMetaData ();
String[] tbl_types = { "TABLE", "VIEW" };
ResultSet rset1 = db_meta.getTables (con.getCatalog (),
schema, "%", tbl_types);
while (rset1.next ()) {
String tbl_name = rset1.getString ("TABLE_NAME");
System.out.println ("Tabelle: " + tbl_name);
ResultSet rset2 = db_meta.getColumns (con.getCatalog (),
schema, tbl_name, "%");
while (rset2.next ()) {
String col_name = rset2.getString ("COLUMN_NAME");
String col_type = rset2.getString ("TYPE_NAME");
int col_size = rset2.getInt ("COLUMN_SIZE");
System.out.println ("\t" + col_name + " " + col_type + "(" +
col_size + ")");
}
System.out.println ();
rset2.close ();
}
rset1.close ();
}
SQLException
Fehler werden wie in Java
üblich über Exceptions mitgeteilt. Für SQL gibt es
die Klasse java.sql.SQLException. Sie ist eine abgleitete Klasse aus java.lang.Exception.
Im Falle eines Fehlers wird ein Objekt der Klasse erzeugt. Will man
also Fehler erkennen muss diese Art von Exception abgefangen werden. In
der Klasse gibt es Methoden um die genaue Fehlerursache zu erkennen, diese
werden in einer SQLException zur Verfügung gestellt.
String getSQLState();
int getErrorCode();
SQLException getNextException();
Prinzipiell mag auch die
ererbete Methode aus java.sql.Throwable
String getMessage()
von Interesse sein. Mit getSQLState
erhält man einen String der in einer standardisierten Form. Mit getErrorCode
erhält man einen Treiberspezifischen Fehlercode und mit getNextException
wird eine weiterere evtl wartende Exception geholt. Ein Beispiel zur Verwendung:
try {
}
catch (SQLException ex) {// A SQLException was generated. Catch it and
// display the error information. Note that there
// could be multiple error objects chained
// togetherSystem.out.println ("\n*** SQLException caught ***\n");
while (ex != null) {
System.out.println ("SQLState: " +
ex.getSQLState ());
System.out.println ("Message: " + ex.getMessage ());
System.out.println ("Vendor: " +
ex.getErrorCode ());
ex = ex.getNextException ();
System.out.println ("");
}
}
Eine typische Verwendung
ist in Zusammenhang mit commit/rollback, dies auch speziell wenn man mehrere
SQL Anweisungen in einen try Block zusammenfasst:
Eine Besonderheit bei der SQL Ausnahmebehandlung ist die Tatsache, dass es nicht nur Fehler gibt. Die Klasse SQLWarning ist von der Klasse SQLException abgeleitet. Der Unterschied ist, dass Warnings nicht zum Verlassen eines Blocks führen, sie müssen daher explizit abgefragt werden:
try {
c.setAutoCommit(false);
...
}
catch (SQLException e) {
c.rollback();
}
SQLWarning getWarning();
void clearWarnings();
und natürlich die Methoden aus SQLException. Ein Programm in dem Warnings abgefangen werden haben typischerweise folgende Form:
Die vielleicht häufigste Warnung betrifft das unvollständige Lesen/Schreiben von Daten. Dafür gibt es eine eigene Klasse DataTruncation, die von SQLWarning abgeleitet wird. Beim Lesen erzeugt dies nur eine Warning, beim Schreiben eine Exception. In SQLstate wird der Code "01004" gespeichert. In der DataTruncation Klasse gibt es dann weitere Methoden
try
{
...stmt = con.createStatement();
sqlw = con.getWarnings();
while( sqlw != null)
{
// handleSQLWarningssqlw = sqlw.getNextWarning();
}
con.clearWarnings();stmt.executeUpdate( sUpdate );
sqlw = stmt.getWarnings();
while( sqlw != null)
{
// handleSQLWarningssqlw = sqlw.getNextWarning();
}
} // end try
catch ( SQLException SQLe)
{
...
} // end catch
int getDataSize();
int getIndex()
boolean getParameter()
boolean getRead();
int getTransferSize();
mit getRead wird festgestellt
ob es sich um eine Lese (true) oder Schreibvorgang ging. getIndex() liefert
die betroffene Spalte der Tabelle. getParameter liefert True wenn es sich
um einen Fehler bei einem Parameter handelt, false wenn es sich um eine
Spalte in einer Tabelle handelt. getDataSize liefert die gewünschte
Grösse der Daten, getTransferSize ist die tatsächliche Grösse
(-1 wenn unbekannt).
scrollable / updatable resultSets
In JDBC 2, das beginnend
ab JDK1.2 ausgeliefert wurde gibt es einige Änderungen gegenüber
der bisher vorgestellten Version JDBC 1. Eine wichtige Änderung betrifft
scrollable und updateable ResultSets. Dazu wurde eine neue CreateStatement
Methode implementiert:
Statement createStatement(
int resultSetType, int resultSetConcurrency )
throws SQLException
für resultSetType gibt es:
ResultSet.TYPE_FORWARD_ONLY--default
wie JDBC 1.0: nur vorwärts, ejde Spalte einmal zu lesen
Falls ResultSet.next() = false, ist das ResultSet nicht mehr
verfügbar und die Daten gelöscht.
ResultSet.TYPE_SCROLL_INSENSITIVE
scroll cursor wie aus embedded SQL für C. Aber statische
Daten: d.h. insensitive gegenüber Änderungen in der Datenbank
ResultSet.TYPE_SCROLL_SENSITIVE
ÄNDERUNGEN IN DER Datenbank werden sichtbar
resultSetConcurrency erlaubt folgende Werte:
ResultSet.CONCUR_READ_ONLY
ResultSet.CONCUR_UPDATABLE d.h im ResultSet können Änderungen
gemacht werden, die in der Datenbank sichtbar werden.
Es gibt auch analoge Befehle
für PreparedStatement und CallableStatement:
PreparedStatement
createStatement( String sql,
int resultSetType, int resultSetConcurrency )
throws SQLException
Statement CallableStatement(
String sql,
int resultSetType, int resultSetConcurrency )
throws SQLException
Hat man dann ein ResultSet
gibt es viele neue Methoden zum Positionieren (ausser dem bekannten next())
void beforeFirst() throws
SQLException;
void afterLast() throws
SQLException;
boolean first() throws
SQLException;
boolean last() throws
SQLException;
ist das ResultSet nicht scrollable
gibt es eine SQLException. Statt next gibt es auch
boolean previous() throws SQLException;
und
boolean absolute (int
row) throws SQLException;
boolean relative (int
row) throws SQLException;
bei absolute bedeutet 1 die
erste Reihe auch -1 ist erlaubt und bedeutet die letzte Reihe. Um hinter
die letzte Reihe zukommen, kann man nur mit next arbeiten, um vor die erste
Reihe zu kommen kann man nur mit previous arbeiten. Um herauszubekommen
wo der Cursor ist
int getRow() throws SQLException;
boolean isLast() throws
SQLException;
boolean isFirst() throws
SQLException;
boolean isAfterLast()
throws SQLException;
boolean isBeforeFirst()
throws SQLException;
Dies betrifft scrollable
ResultSets. Bei updateable ResultSets, d.h. bei Statement Objekten mit
dem Parameter CONCUR_UPDATABLE erzeugt. Um die folgenden Methoden zu verwenden
muss es natürlich für den Server möglich sein eine Änderung
zu machen. Das geht natürlich nicht bei allen resultSets. Um ein Update
zu machen gibt es analog zu getXXX Methoden in der Klasse ResultSet einen
Satz von
void updateString(int
index) throws SQLException
void updateString(String
name) throws SQLException
void updateInt(int index)
throws SQLException
void updateInt(String
name) throws SQLException
...
damit werden die Werte der
aktuellen Zeile geändert, um diese Änderung in der Datenbank
wirksam zu machen verwendet man die Methode
void updateRow() throws
SQLException;
ändert man die Position
der Zeile ohne den Aufruf der updateRow Methode werden die Änderungen
verworfen, was man auch durch
void cancelRowUpdates()
throws SQLException;
erreichen kann. Will man
eine Zeile einfügen erzeugt man eine leere Zeile im resultSet mit
void moveToInsertRow()
throws SQLException;
void insertRow() throws
SQLException;
void moveToCurrentRow()
throws SQLException;
mit insertRow wird nach updateXXX
die Zeile eingefügt mit moveTo... kann man wieder zur vorherigen Position
im ResultSet gelangen. Dazu ein Beispiel aus der Sun Dokumentation:
import java.sql.*;Zum Löschen gibt es noch die Routinepublic class InsertRows {
public static void main(String args[]) {
String url = "jdbc:mySubprotocol:myDataSource";
Connection con;
Statement stmt;
try {
Class.forName("myDriver.ClassName");
} catch(java.lang.ClassNotFoundException e) {
System.err.print("ClassNotFoundException: ");
System.err.println(e.getMessage());
}
try {
con = DriverManager.getConnection(url, "myLogin", "myPassword");
stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_UPDATABLE);
ResultSet uprs = stmt.executeQuery("SELECT * FROM COFFEES");
uprs.moveToInsertRow();
uprs.updateString("COF_NAME", "Kona");
uprs.updateInt("SUP_ID", 150);
uprs.updateFloat("PRICE", 10.99f);
uprs.updateInt("SALES", 0);
uprs.updateInt("TOTAL", 0);
uprs.insertRow();
uprs.updateString("COF_NAME", "Kona_Decaf");
uprs.updateInt("SUP_ID", 150);
uprs.updateFloat("PRICE", 11.99f);
uprs.updateInt("SALES", 0);
uprs.updateInt("TOTAL", 0);
uprs.insertRow();
uprs.beforeFirst();
System.out.println("Table COFFEES after insertion:");
while (uprs.next()) {
String name = uprs.getString("COF_NAME");
int id = uprs.getInt("SUP_ID");
float price = uprs.getFloat("PRICE");
int sales = uprs.getInt("SALES");
int total = uprs.getInt("TOTAL");
System.out.print(name + " " + id + " " + price);
System.out.println(" " + sales + " " + total);
}uprs.close();
stmt.close();
con.close();} catch(SQLException ex) {
System.err.println("SQLException: " + ex.getMessage());
}
}
void deleteRow() throws
SQLException;
da Änderungen sich auch
im resultSet auswirken gibt es die Methode
void refreshRow() throws
SQLException;
neue Datentypen
eine weitere wichtige Neuerung
sind die Unterstützung weiterer interner Datentypen, im wesentlichen
handelt es sich um SQL Datentypen die in der neuen SQL Version (SQL99)
definiert werden:
| BLOB | binary large object |
| CLOB | charcter large object |
| REF | Referenz |
| ARRAY | array |
| struct | Benutzerdefiniert |
das bedeutet auch, dass entsprechende
getXXX und setXXX updateXXX Methoden vorhanden sein müssen.
Hierbei handelt es sich
nicht um weitere JDBC spezifische Methoden, sondern es soll vorgestellt
werden wie die JDBC in ein Applet eingebunden werden um eine Darstellung
von Datenbankabfragen im WWW zu ermöglichen.
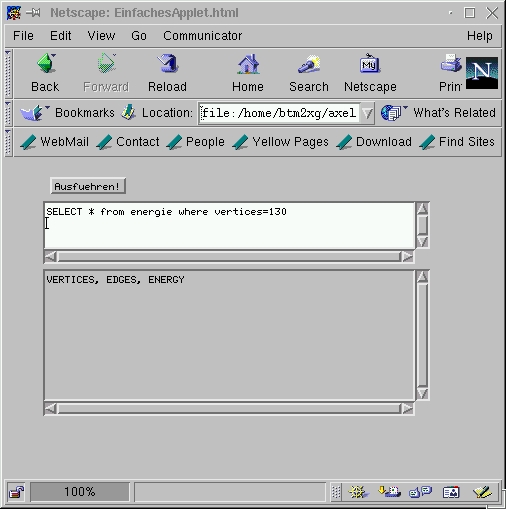
Dies ist ein Beispiel, indem eine Datenbankverbindung aufgebaut wird und nachfolgend kann man SQL Befehle direkt eingeben. Der erste Schritt ist HTML source code mit dem Aufruf eines Applets:
<TITLE>EinfachesApplet.html</TITLE>
<APPLET Code=EinfachesApplet.class
Height=300 Width=450 >
</APPLET>
das ist alles, der interessantere
Teil ist der Java source code mit Namen EinfachesApplet.java
import java.sql.*;
import java.awt.*;
import java.awt.event.*;public class EinfachesApplet extends java.applet.Applet
implements ActionListener {
// GUI-Komponenten
Button ausfuehren = new Button("Ausfuehren!");
TextArea ein = new TextArea("SELECT", 3, 60);
TextArea ausgabe = new TextArea();
// DBMS-Variable
Connection c;
Statement s;public void init() {
Panel eingabe = new Panel(new BorderLayout());
Panel knopf = new Panel(new FlowLayout(FlowLayout.LEFT));
knopf.add(ausfuehren);
eingabe.add(knopf, "North");
eingabe.add(ein, "Center");
add(eingabe, "North");
add(ausgabe, "Center");
ausgabe.setEditable(false); // fuer Eingaben sperren
setSize(450, 300); // Fenstergröße
setVisible(true); // Fenster anzeigen
try {
String url = "jdbc:yardjdbc://localhost:1142/sample/SYMMETRICA";
Class.forName("yardjdbc.YardDriver");
c = DriverManager.getConnection(url, "axel","verratichnicht");
s = c.createStatement();
}
catch (Exception ex) {
ausgabe.setText("Fehler:\n" + ex.getMessage());
}
ausfuehren.addActionListener(this); // Eventlistener reg.
}public void actionPerformed(ActionEvent e) {
String sql = ein.getText();
ResultSet r;
try {
if (s.execute(sql)) { // SQL SELECT ausfuehren
r = s.getResultSet();
ResultSetMetaData rm = r.getMetaData();
int x = rm.getColumnCount();
ausgabe.setText("");
for (int i = 1; i <= x; i++) {
ausgabe.append(rm.getColumnName(i));
if (i != x) ausgabe.append(", ");
else ausgabe.append("\n");
}
while(r.next()) {
for (int i = 1; i <= x; i++) {
ausgabe.append(r.getString(i));
if (i != x) ausgabe.append(", ");
else ausgabe.append("\n");
}
}
}
else
ausgabe.setText(String.valueOf(s.getUpdateCount()));
}
catch (Exception ex) {
ausgabe.setText("SQL: " + sql + "\nFehler:\n" +
ex.getMessage());
}
}
} // Ende class EinfachesApplet
In JDK1.2 wurde ein neues
graphisches Benutzerinterface eingeführt, das sog. SWING package.
Literatur:
Geary:Graphic Java Mastering
the JFC Vol. 2 Swing
Sun online Dokumentation
Ein wichtiger Bestandteil
des SWING package ist das JTable Objekt, welches hervorragend geeignet
ist ein ResultSet darzustellen. Im folgenden soll ein Beispielprogramm
aus dem JDK 1.2 Paket besprochen werden. Das Programm besteht aus zwei
Fenstern, dem ersten Fenster um eine Verbindung zur Datenbank aufzubauen,
hierzu muss im wesentlichen URL, Benutzername und Passwort eingegeben werden.
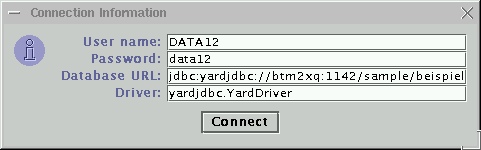
Im zweiten Fenster kann man SQL Befehle eingeben und das ResultSet wird dargestellt. Dies ist ähnlich dem schon bekannten Applet.
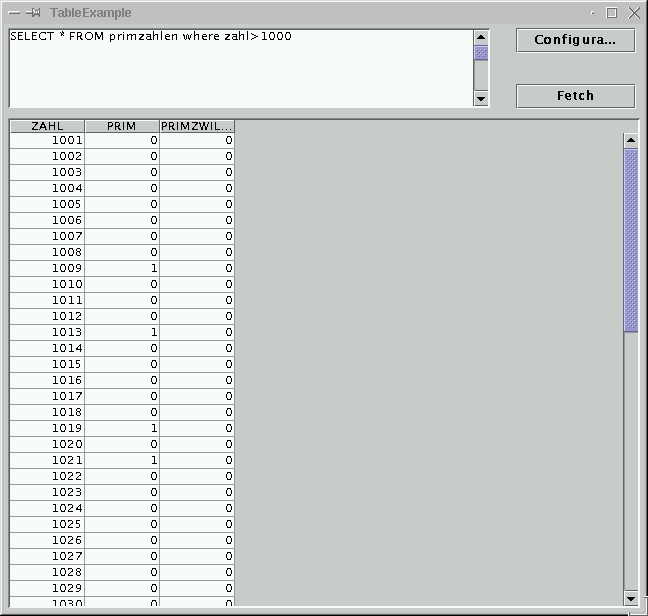
Um mit einem JTable Objekt zu arbeiten, muss beim Anlegen der JTable Information über die Tabelle übergeben werden. Man kann dies direkt tun
public JTable(Vector rowData,
Vector columnNames)
public JTable(Object[][]
rowData, Object[] columnNames)
oder aber über sog.
TableModel Objekte, diese stellen Methoden zur Verfügung um auf die
Einträge der Tabelle zu zugreifen. Diese Vorgehensweise bietet sich
für die Zusammenarbeit mit einer Datenbank an. In diesem Beispiel
wird die Klasse AbstractTableModel verwendet. Zuerst betrachten wir daher
die Klasse JDBCAdapter die davon abgeleitet wird:
/**Bereits beim Anlegen des JDBCAdapter Objekts wird eine Verbindung aufgebaut und ein Statement angelegt
* An adaptor, transforming the JDBC interface to the TableModel interface.
*
* @version 1.20 09/25/97
* @author Philip Milne
*/import java.util.Vector;
import java.sql.*;
import javax.swing.table.AbstractTableModel;
import javax.swing.event.TableModelEvent;public class JDBCAdapter extends AbstractTableModel {
Connection connection;
Statement statement;
ResultSet resultSet;
String[] columnNames = {};
Vector rows = new Vector();
ResultSetMetaData metaData;public JDBCAdapter(String url, String driverName,
String user, String passwd) {
try {
Class.forName(driverName);
System.out.println("Opening db connection");connection = DriverManager.getConnection(url, user, passwd);
statement = connection.createStatement();
}
catch (ClassNotFoundException ex) {
System.err.println("Cannot find the database driver classes.");
System.err.println(ex);
}
catch (SQLException ex) {
System.err.println("Cannot connect to this database.");
System.err.println(ex);
}
}
public void executeQuery(String query) {Nach einer Abfrage wird der Inhalt der Datenbank lokal kopiert.
if (connection == null || statement == null) {
System.err.println("There is no database to execute the query.");
return;
}
try {
resultSet = statement.executeQuery(query);
metaData = resultSet.getMetaData();int numberOfColumns = metaData.getColumnCount();
columnNames = new String[numberOfColumns];
// Get the column names and cache them.
// Then we can close the connection.
for(int column = 0; column < numberOfColumns; column++) {
columnNames[column] = metaData.getColumnLabel(column+1);
}// Get all rows.
rows = new Vector();
while (resultSet.next()) {
Vector newRow = new Vector();
for (int i = 1; i <= getColumnCount(); i++) {
newRow.addElement(resultSet.getObject(i));
}
rows.addElement(newRow);
}fireTableChanged(null); // Tell the listeners a new table has arrived.
}
catch (SQLException ex) {
System.err.println(ex);
}
}
public void close() throws SQLException {Das sind die Methoden die bei einem TableModel da sein müssen
System.out.println("Closing db connection");
resultSet.close();
statement.close();
connection.close();
}protected void finalize() throws Throwable {
close();
super.finalize();
}//////////////////////////////////////////////////////////////////////////
//
// Implementation of the TableModel Interface
//
//////////////////////////////////////////////////////////////////////////
// MetaDataDamit kann man schon ein einfaches Java Programm schreiben um auf eine JDBC Datenbank zuzugreifen:public String getColumnName(int column) {
if (columnNames[column] != null) {
return columnNames[column];
} else {
return "";
}
}public Class getColumnClass(int column) {
int type;
try {
type = metaData.getColumnType(column+1);
}
catch (SQLException e) {
return super.getColumnClass(column);
}switch(type) {
case Types.CHAR:
case Types.VARCHAR:
case Types.LONGVARCHAR:
return String.class;case Types.BIT:
return Boolean.class;case Types.TINYINT:
case Types.SMALLINT:
case Types.INTEGER:
return Integer.class;case Types.BIGINT:
return Long.class;case Types.FLOAT:
case Types.DOUBLE:
return Double.class;case Types.DATE:
return java.sql.Date.class;default:
return Object.class;
}
}public boolean isCellEditable(int row, int column) {
try {
return metaData.isWritable(column+1);
}
catch (SQLException e) {
return false;
}
}public int getColumnCount() {
return columnNames.length;
}// Data methods
public int getRowCount() {
return rows.size();
}public Object getValueAt(int aRow, int aColumn) {
Vector row = (Vector)rows.elementAt(aRow);
return row.elementAt(aColumn);
}public String dbRepresentation(int column, Object value) {
int type;if (value == null) {
return "null";
}try {
type = metaData.getColumnType(column+1);
}
catch (SQLException e) {
return value.toString();
}switch(type) {
case Types.INTEGER:
case Types.DOUBLE:
case Types.FLOAT:
return value.toString();
case Types.BIT:
return ((Boolean)value).booleanValue() ? "1" : "0";
case Types.DATE:
return value.toString(); // This will need some conversion.
default:
return "\""+value.toString()+"\"";
}}
public void setValueAt(Object value, int row, int column) {
try {
String tableName = metaData.getTableName(column+1);
// Some of the drivers seem buggy, tableName should not be null.
if (tableName == null) {
System.out.println("Table name returned null.");
}
String columnName = getColumnName(column);
String query =
"update "+tableName+
" set "+columnName+" = "+dbRepresentation(column, value)+
" where ";
// We don't have a model of the schema so we don't know the
// primary keys or which columns to lock on. To demonstrate
// that editing is possible, we'll just lock on everything.
for(int col = 0; col<getColumnCount(); col++) {
String colName = getColumnName(col);
if (colName.equals("")) {
continue;
}
if (col != 0) {
query = query + " and ";
}
query = query + colName +" = "+
dbRepresentation(col, getValueAt(row, col));
}
System.out.println(query);
System.out.println("Not sending update to database");
// statement.executeQuery(query);
}
catch (SQLException e) {
// e.printStackTrace();
System.err.println("Update failed");
}
Vector dataRow = (Vector)rows.elementAt(row);
dataRow.setElementAt(value, column);}
}
/**Basisobjekt in SWING
* A minimal example, using the JTable to view data from a database.
*
* @version 1.20 09/25/97
* @author Philip Milne
*/import javax.swing.*;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.awt.Dimension;public class TableExample2 {
public TableExample2(String URL, String driver, String user,
String passwd, String query) {
JFrame frame = new JFrame("Table");
frame.addWindowListener(new WindowAdapter() {Damit das Programm aufhört wenn man auf Aufhören (X) klickt
public void windowClosing(WindowEvent e) {System.exit(0);}});
JTable sollen immer in ein JScrollPane
JDBCAdapter dt = new JDBCAdapter(URL, driver, user, passwd);
dt.executeQuery(query);// Create the table
JTable tableView = new JTable(dt);JScrollPane scrollpane = new JScrollPane(tableView);
scrollpane.setPreferredSize(new Dimension(700, 300));
Damit erhält man als Ausgabe das schon vorgestellte Bild.
frame.getContentPane().add(scrollpane);
frame.pack();
frame.setVisible(true);
}public static void main(String[] args) {
if (args.length != 5) {
System.err.println("Needs database parameters eg. ...");
System.err.println("java TableExample2 \"jdbc:sybase://dbtest:1455/pubs2\" \"connect.sybase.SybaseDriver\" guest trustworthy \"select * from titles\"");
return;
}
new TableExample2(args[0], args[1], args[2], args[3], args[4]);
}
}